How to Build an Object Detection Model using Convolutional Neural Networks and Transfer Learning in Keras with Mask RCNN Library.
Jul 24, 2020
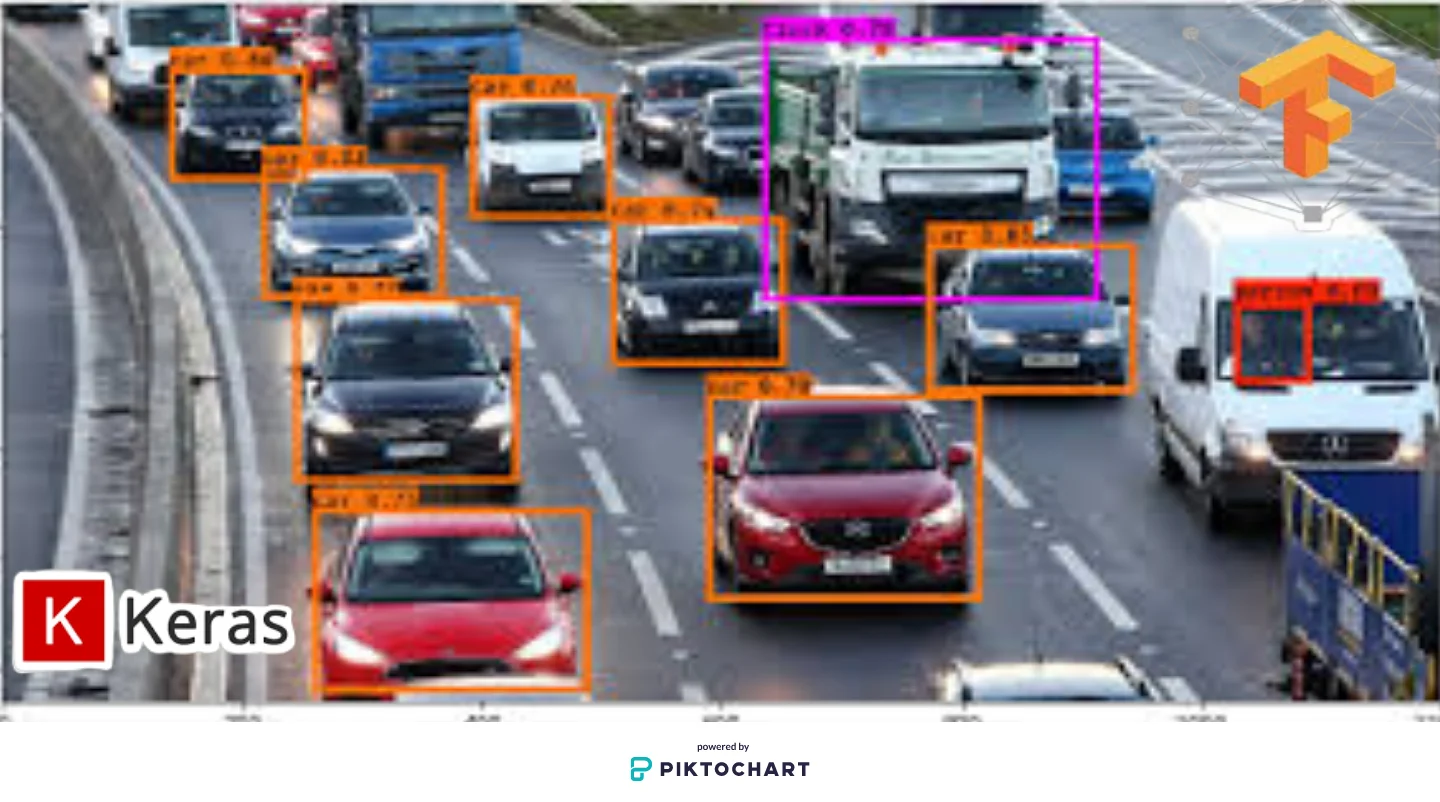
In this tutorial you would see how to apply state-of-the-art R-CNN architecture model built on the MS Coco dataset for Object Detection on a new Dataset. We use Transfer Learning for efficient and faster training epochs. You would learn how to Install the R-CNN Library, install the dataset we want to make predictions on, parse the annotation files for bounding boxes, Train Mask R-CNN Model on dataset using Transfer Learning.
Overview
- Gentle introduction to Object Detection
- Object Detection task in Computer Vision using Mask R-CNN
- Preparing R-CNN library Model
- Installing the Dataset (Kangaroo)
- Training Mask R-CNN Model on Dataset using Transfer Learning
- Detecting Kangaroo in new Images.
Now that you have an idea of the stepss taking us through this tutorial, Let’s begin with it.
Introduction
Object Detection is a Computer Vision task that involves identifying the presence, location, and class of one or more objects in an image. It is a challenging problem that involves building upon methods for Object recognition (e.g. where are they), object localization (e.g. what are their extent), and object classification (e.g. what are they).
In this tutorial, we are going to use the Region based Convolutional Neural network (R-CNN) to perform object Detection and idetify kangaroos in images. This pre-built model can be used on other datasets to identify other classes of images. For now, we look at a single class (i.e kangaroo) of image.
We want our model to predict the objects in unseen images and draw a bounding box around them. As we implement this simple task using a simgle class of image, we can get a better understanding of this task and later move on to larger classes of images like in the Coco Dataset.
Here, instead of developing an implementation of the R-CNN or Mask R-CNN model from scratch, we can use a reliable third-party implementation built on top of the Keras deep learning framework. The best-of-breed third-party implementations of Mask R-CNN is the Mask R-CNN Project developed by Matterport. The project is open source released under a permissive license (e.g. MIT license) and the code has been widely used on a variety of projects and Kaggle competitions. Let’s Begin.
For this tutorial, some libraries used are not avvailable in tensorflow 2x, please use 1x for this tutorial. Ro change the version you arerunning in colab, use the code below. If you are following this guide on your machine you can create a virtual and install tensorflow 1x.
Install Tensorflow 1x
#%tensorflow_version 1.x
#import tensorflow as tf
print(tf.__version__)
Installing the R-CNN library
This involves:
- Cloning github repo
- Running the installation script
To git clone in Colab like I am doing, use the code below. If you are doing this locally on your machine, write the code without the exclamation mark “git clone https://github.com/matterport/Mask_RCNN.git”
!git clone https://github.com/matterport/Mask_RCNN.git
After running the above,, a new directory “Mask_RCNN” should appear in the files section on colab. And like-wise, a local-directory should be created on your machine. It comes with the following folders:
- assets
- images
- samples
- mrcnn etc.. Next, we can install the library by moving into Mask_RCNN directory and running the code below.
If you are using Google Colab for this guide,, to change directory use the last two lines in the code below,, otherwise use the first two after uncommenting them.
#cd /content/Mask_RCNN/
#python setup.py install
%cd /content/Mask_RCNN
!python setup.py install
After running this, the success messages confirms that you installed the library successfully and that you have the latest version, which at the time of writing is version 2.1.
To be sure, we can confirm the library installed properly using the code below.
#Use first line if your are implementing on a local machine, other wise use the second line
#pip show mask-rcnn
!pip show mask-rcnn
Preparing dataset for Object detection
Next, we would start to work with the dataset. We are using the Kangaroo dataset by Huynh Ngoc Anh. It consists of 183 photographs that contain kangaroos, and XML annotation files that provide bounding boxes for the kangaroos in each photograph. We would use mask-rcnn model to perform object detection on the dataset. The R-CNN library is built to perform both object detection tasks and masking, but the kangoroo datatset does not provide mask so we would be focusing on the object detection task here.
In the next few sections, we look at how to prepare the dataset by downloading, parsing annotations and developing a KangarooDataset object that can be used by Mask_RCNN library.
Installing the Dataset
Follow the code below to download the kangaroo dataset by cloning it directly from the github repo. A kangaroo directory is created with two sub-directories images and annotes which contain JPEG photos of kangaroos and XML files describing the locations of their bounding boxes respectively.
#git clone https://github.com/experiencor/kangaroo.git
!git clone https://github.com/experiencor/kangaroo.git
Parsing Annotation File
Next, we can parse the annots subdirectory containing the size and locations of each object in pictures from the dataset. We can use Python ElementTree API to get fast results. ElementTree API can be used to load and parse an XML file and we can use the find() and findall() functions to perform the XPath queries on a loaded document.
Let’s understand how this would work by looking at a file from annots. Open up the first file “00001.xml”. On Colab, you can download the file and open it with Sublime text or any other text-editor. It looks like this:
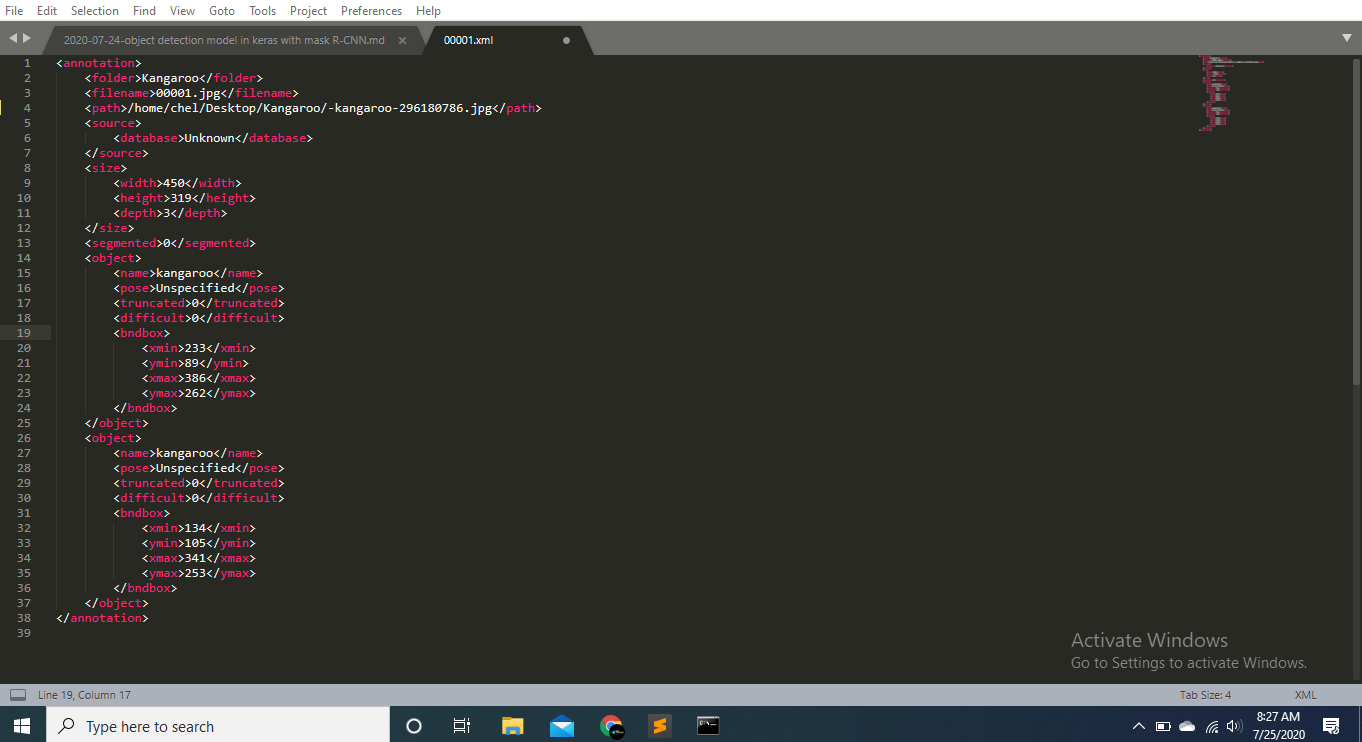
We can see that it has a size, two objects and two bndbox elements. This is what would define ;
The size of the image The number of objects in a photo The bounding box location of each object. First, the annotation file must be loaded and parsed as an ElementTree object. Use the code below to do that.
from xml.etree import ElementTree
import os
# load and parse the file
path = '/content/Mask_RCNN/kangaroo/annots'
for filename in os.listdir(path):
if not filename.endswith('.xml'): continue
fullname = os.path.join(path, filename)
tree = ElementTree.parse(fullname)
Once loaded, we can retrieve the root element of the document from which we can perform our XPath queries.
# get the root of the document
root = tree.getroot()
We can use the findall() function with a query for ‘.//bndbox‘ to find all ‘bndbox‘ elements, then enumerate each to extract the x and y, min and max values that define each bounding box.
The element text can also be parsed to integer values.
We can then collect the definition of each bounding box into a list (coors)
# extract each bounding box
for box in root.findall('.//bndbox'):
xmin = int(box.find('xmin').text)
ymin = int(box.find('ymin').text)
xmax = int(box.find('xmax').text)
ymax = int(box.find('ymax').text)
coors = [xmin, ymin, xmax, ymax]
print(coors
The Image Dimensions may also be needed, we can query that directly
# extract image dimensions
width = int(root.find('.//size/width').text)
height = int(root.find('.//size/height').text)
print(width,height)
For ease of use, we can define a function that that takes all the process above and implements it in the steps below when it is called.
Get annotation filename as an argument Extract the bounding box using the xmin, ymin, xmax, ymax values. Extract the image dimension details from the width & height values. Return them for use The function extract_all() in the code cell below implements this behaviour.
def extract_all(filename):
# load and parse the file
tree = ElementTree.parse(filename)
# get the root of the document
root = tree.getroot()
# extract each bounding box
boxes = list()
for box in root.findall('.//bndbox'):
xmin = int(box.find('xmin').text)
ymin = int(box.find('ymin').text)
We can test out this function on our annotation files. Let’s pick the first file for this test.
# extract details form annotation file
boxes, w, h = extract_all('kangaroo/annots/00001.xml')
# summarize extracted details
print(boxes, w, h)
Developing Kangaroo Dataset Object The mask-rcnn library requires that train, validation, and test datasets be called by a mrcnn.utils.Dataset object. This means that a new class must be defined that extends the mrcnn.utils.Dataset class and defines a function to load the dataset, with any name you like such as load_dataset(), and override two functions, one for loading a mask called load_mask() and one for loading an image reference (path or URL) called image_reference().
class that defines and loads the kangaroo dataset
To use a Dataset object, it is instantiated, then your custom load function must be called, then finally the built-in prepare() function is called.
Let’s do that in the code cell below.
# prepare the dataset
#train_set = KangarooDataset()
#train_set.load_dataset(...)
#train_set.prepare()
The custom load function, e.g. load_dataset() is responsible for both defining the classes and for defining the images in the dataset.
Classes are defined by calling the built-in add_class() function and specifying the ‘source‘ (the name of the dataset), the ‘class_id‘ or integer for the class (e.g. 1 for the first class as 0 is reserved for the background class), and the ‘class_name‘ (e.g. ‘kangaroo‘).
# define one class
#self.add_class("dataset", 1, "kangaroo")
Objects are defined by a call to the built-in add_image() function and specifying the ‘source‘ (the name of the dataset), a unique ‘image_id‘ (e.g. the filename without the file extension like ‘00001‘), and the path for where the image can be loaded (e.g. ‘kangaroo/images/00001.jpg‘).
This will define an “image info” dictionary for the image that can be retrieved later via the index or order in which the image was added to the dataset. You can also specify other arguments that will be added to the image info dictionary, such as an ‘annotation‘ to define the annotation path.
# define one image
# add to dataset
#self.add_image('dataset', image_id='00001', path='kangaroo/images/00001.jpg', annotation='kangaroo/annots/00001.xml')
Next, we can implement a load_dataset() function that takes the path to dataset directory and loads all image in it. Image with number ‘00090‘ has an issue, so it would be excluded when we write code to load all images. We can also devide the dataset when loading into training and validation sets. The full photos are about 160. In a 80/20 ratio, we are left with about 131 photos in the training set and 20 in validation.
# load the dataset definitions
def load_dataset(self, dataset_dir, is_train=True):
# define one class
self.add_class("dataset", 1, "kangaroo")
# define data locations
images_dir = dataset_dir + '/images/'
annotations_dir = dataset_dir + '/annots/'
# find all images
for filename in listdir(images_dir):
# extract image id
Next, we need to define the load_mask() function for loading the mask for a given ‘image_id‘. Here, we use load_mask() function to call an image with its id. The id here is the integer value assigned to all images when loading them from the dataset. They are arranged in incresing order. The id of the image corresponds to that of our annotation, therefore we substitute loading masks which we don’t have for xml files describing bounding boxes for an image.
To retrieve the annotation on each files we must specify the path to the files, then we can use the function extract_all we defined earlier to get the x,y points in an image describing the bounding boxes and dimensions. Note: self.image_info is a built-in function
# get details of image
#info = self.image_info[image_id]
# define box file location
#path = info['annotation']
# load XML
#boxes, w, h = self.extract_boxes(path)
We can now define a mask value for the images. A mask is a two-dimensional array with the same dimensions as the photograph with all zero values where the object isn’t and one values where the object is.
We can achieve this by creating a NumPy array with all zero values for the known size of the image and one channel for each bounding box.
import numpy as np
# create one array for all masks, each on a different channel
masks = zeros([h, w, len(boxes)], dtype='uint8')
Each bounding box is defined as min and max, x and y coordinates of the box.
These can be used directly to define row and column ranges in the array that can then be marked as 1.
# create masks
#for i in range(len(boxes)):
# box = boxes[i]
# row_s, row_e = box[1], box[3]
# col_s, col_e = box[0], box[2]
# masks[row_s:row_e, col_s:col_e, i] = 1
All objects have the same class in this dataset. We can retrieve the class index via the ‘class_names‘ dictionary, then add it to a list to be returned alongside the masks.
#self.class_names.index(‘kangaroo’) Putting all this together,, we have a load_dataset() function that looks like below.
# load the masks for an image
def load_mask(self, image_id):
# get details of image
info = self.image_info[image_id]
# define box file location
path = info['annotation']
# load XML
boxes, w, h = self.extract_boxes(path)
# create one array for all masks, each on a different channel
masks = zeros([h, w, len(boxes)], dtype='uint8')
Finally, we must implement the image_reference() function.
This function is responsible for returning the path or URL for a given ‘image_id’.
# load an image reference
def image_reference(self, image_id):
info = self.image_info[image_id]
return info['path']
And that’s it. We have successfully defined a Dataset object for the mask-rcnn library for our Kangaroo dataset.
The complete code for loading our dataset, defining the path for object bounding boxes, creating a mask for images and so on is below
split into train and test set
from os import listdir from xml.etree import ElementTree from numpy import zeros from numpy import asarray from mrcnn.utils import Dataset
class that defines and loads the kangaroo dataset
class KangarooDataset(Dataset): # load the dataset definitions
Now that we have defined the dataset, let’s confirm that the images, masks, and bounding boxes are handled correctly
Testing KangarooDataset Object Now we are gonna confirm that this works properly. We are gonna load an image by specifying an image_id and calling it with the load_image function and likewise, the mask of the image by calling load_mask function with the same image_id. Let’s do that in the code cell below.
# load an image
image_id = 1
image = train_set.load_image(image_id)
print(image.shape)
# load image mask
mask, class_ids = train_set.load_mask(image_id)
print(mask.shape)
Next, we can plot the photograph using the Matplotlib Library. We can then plot the mask over the image, we specify an alpha value for the mask here so that it remains transparent and we can still see the image underneath.
from matplotlib import pyplot
#plot the image
pyplot.imshow(image)
# plot mask
pyplot.imshow(mask[:, :, 0], cmap='gray', alpha=0.5)
pyplot.show()
The complete code for the example is listed below
plot one photograph and mask
from os import listdir from xml.etree import ElementTree from numpy import zeros from numpy import asarray from mrcnn.utils import Dataset from matplotlib import pyplot
class that defines and loads the kangaroo dataset
class KangarooDataset(Dataset): </b>
Running the example first prints the shape of the photograph and then the masks.
We can confirm that both arrays have the same width and height and only differ in terms of the number of channels. We can also see that the first photograph (e.g. image_id=0) in this case only has one mask.
A plot of the photograph is also created with the first mask overlaid.
In this case, we can see that one kangaroo is present in the photo and that the mask correctly bounds the kangaroo.
We could repeat this for the first nine photos in the dataset, plotting each photo in one figure as a subplot and plotting all masks for each photo.
plot first few images
for i in range(9): # define subplot pyplot.subplot(330 + 1 + i) # plot raw pixel data image = train_set.load_image(i) pyplot.imshow(image) # plot all masks mask, _ = train_set.load_mask(i) for j in range(mask.shape[2]):
Running this plots 9 images with the masks of each placed correctly. Also images with multiple kangaroo objects have separate mask defined.
Finally, the mask-rcnn library provides utilities for displaying images and masks. We can use some of these built-in functions to confirm that the Dataset is operating correctly.
For example, the mask-rcnn library provides the mrcnn.visualize.display_instances() function that will show a photograph with bounding boxes, masks, and class labels. This requires that the bounding boxes are extracted from the masks via the extract_bboxes() function.
display image with masks and bounding boxes
from os import listdir from xml.etree import ElementTree from numpy import zeros from numpy import asarray from mrcnn.utils import Dataset from mrcnn.visualize import display_instances from mrcnn.utils import extract_bboxes
class that defines and loads the kangaroo dataset
Running the example creates a plot showing the photograph with the mask for each object in a separate color.
The bounding boxes match the masks exactly, by design, and are shown with dotted outlines. Finally, each object is marked with the class label, which in this case is ‘kangaroo‘.
Training Mask RCNN Model on kangaroo Dataset Using Transfer Learning We can fit/train a new model using the RCNN architecture from scratch to make predictions on new dataset but that would just be a waste of time. Time can be saved and performance improved by using Transfer Learning.
The first step to using tranfer learning is to download the weights of our pre-fit in our case RCNN. This can be found in the github project.
Download here Download Weights (mask_rcnn_coco.h5) 246M
To download directly to colab without having to upload to colab from your sysatem use the code cell below:
!wget https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
Next we must define a configuration object that extends the mrcnn.config.Config class. It should take in properties for the prediction problem like name and number of class and the algorithm for training like the learning rate.
The configuration must define the name of the configuration via the ‘NAME‘ attribute, e.g. ‘kangaroo_cfg‘, that will be used to save details and models to file during the run. The number of classes in the prediction problem must also be defined via the ‘NUM_CLASSES‘ attribute. In this case, we have only one object type of kangaroo,although there is always an additional class for the background.
Lastly, the number of samples which is the number of training examples or images must be defined, 132 in this case.
Now after adding the required, our custom KangarooConfig file would look like this:
[ ]
fit a mask rcnn on the kangaroo dataset
from os import listdir from xml.etree import ElementTree from numpy import zeros from numpy import asarray from mrcnn.utils import Dataset from mrcnn.config import Config from mrcnn.model import MaskRCNN
class that defines and loads the kangaroo dataset
#define a configuration for the model
class KangarooConfig(Config):
# Give the configuration a recognizable name
NAME = "kangaroo_cfg"
# Number of classes (background + kangaroo)
NUM_CLASSES = 1 + 1
# Number of training steps per epoch
STEPS_PER_EPOCH = 131
# prepare config
Next we would define our model, this is achieved by creating an instance of the mrcnn.model.MaskRCNN class and specifying the model will be used for training via setting the ‘mode‘ argument to ‘training‘. We would also create an instance of our KangarooConfig file in the config parameter. A directory would then be pointed to where configuration files can be saved and for saving checkpoints of the model at the end of each epochs. the current working directory can be used. Let’s do that now:
define the model
model = MaskRCNN(mode=’training’, model_dir=’./’, config=config) </b> Before we proceed to loading the model weights, we can define a new variable that would hold the fuction we created earlier that loads the training and test test. We would need this data later when we finally start training. The code below shows how to do this:
# prepare train set
train_set = KangarooDataset()
train_set.load_dataset('kangaroo', is_train=True)
train_set.prepare()
print('Train: %d' % len(train_set.image_ids))
# prepare test/val set
test_set = KangarooDataset()
test_set.load_dataset('kangaroo', is_train=False)
test_set.prepare()
print('Test: %d' % len(test_set.image_ids))
Next, the pre-define model weights can be loaded, we specify a path to the saved weights “mask_rcnn_coco.h5”, we call the load_weights function on model defined above.
The model will be used as it is, although the class-specific output layers will be removed so that new output layers can be defined and trained. This can be done by specifying the ‘exclude‘ argument and listing all of the output layers to exclude or remove from the model after it is loaded. This includes the output layers for the classification label, bounding boxes, and masks.
# load weights (mscoco)
model.load_weights('mask_rcnn_coco.h5', by_name=True, exclude=["mrcnn_class_logits", "mrcnn_bbox_fc", "mrcnn_bbox", "mrcnn_mask"])
Next, the model can be fit on the training dataset by calling the train() function and passing in both the training dataset and the validation dataset. We can also specify the learning rate as the default learning rate in the configuration (0.001).
We can also specify what layers to train. In this case, we will only train the heads, that is the output layers of the model.
[ ]
train weights (output layers or ‘heads’)
model.train(train_set, test_set, learning_rate=config.LEARNING_RATE, epochs=5, layers=’heads’) We could train this for more epochs that fine-tune all of the weights in the model. This could also be achieved by using a smaller learning rate and changing the ‘layer’ argument from ‘heads’ to ‘all’.
Running this training step can take a bit of time to execute on a modern CPU, if you are running on colab, you can switch to a GPU by clicking the Runtime and selecting change runtime.
We can see that there are many different train and test loss scores reported for each of the output heads of the network. It can be quite confusing as to which loss to pay attention to.
In this example where we are interested in object detection instead of object segmentation, I recommend paying attention to the loss for the classification output on the train and validation datasets (e.g. mrcnn_class_loss and val_mrcnn_class_loss), as well as the loss for the bounding box output for the train and validation datasets (mrcnn_bbox_loss and val_mrcnn_bbox_loss).
A model file is created and saved at the end of each epoch in a subdirectory that starts with ‘kangaroo_cfg‘ followed by random characters.
A model must be selected for use; in this case, the loss continues to decrease for the bounding boxes on each epoch, so we will use the final model at the end of the run (‘mask_rcnn_kangaroo_cfg_0005.h5‘).
Copy the model file from the config directory into your current working directory. We will use it in the following sections to evaluate the model and make predictions.
The results suggest that perhaps more training epochs could be useful, perhaps fine-tuning all of the layers in the model.
Next, let’s look at evaluating the performance of this model.
Evaluating a Mask R-CNN Model The performance of a model for an object recognition task is often evaluated using the mean absolute precision, or mAP.
We are predicting bounding boxes so we can determine whether a bounding box prediction is good or not based on how well the predicted and actual bounding boxes overlap. This can be calculated by dividing the area of the overlap by the total area of both bounding boxes, or the intersection divided by the union, referred to as “intersection over union,” or IoU. A perfect bounding box prediction will have an IoU of 1.
It is standard to assume a positive prediction of a bounding box if the IoU is greater than 0.5, e.g. they overlap by 50% or more.
Precision refers to the percentage of the correctly predicted bounding boxes (IoU > 0.5) out of all bounding boxes predicted. Recall is the percentage of the correctly predicted bounding boxes (IoU > 0.5) out of all objects in the photo.
As we make more predictions, the recall percentage will increase, but precision will drop or become erratic as we start making false positive predictions. The recall (x) can be plotted against the precision (y) for each number of predictions to create a curve or line. We can maximize the value of each point on this line and calculate the average value of the precision or AP for each value of recall.
Note: there are variations on how AP is calculated, e.g. the way it is calculated for the widely used PASCAL VOC dataset and the MS COCO dataset differ.
The average or mean of the average precision (AP) across all of the images in a dataset is called the mean average precision, or mAP.
The mask-rcnn library provides a mrcnn.utils.compute_ap to calculate the AP and other metrics for a given images. These AP scores can be collected across a dataset and the mean calculated to give an idea at how good the model is at detecting objects in a dataset.
First, we must define a new Config object to use for making predictions, instead of training. We can extend our previously defined KangarooConfig to reuse the parameters. Instead, we will define a new object with the same values to keep the code compact. The config must change some of the defaults around using the GPU for inference that are different from how they are set for training a model (regardless of whether you are running on the GPU or CPU).
[ ]
define the prediction configuration
class PredictionConfig(Config): # define the name of the configuration NAME = “kangaroo_cfg” # number of classes (background + kangaroo) NUM_CLASSES = 1 + 1 # simplify GPU config GPU_COUNT = 1 IMAGES_PER_GPU = 1 Next, we can define the model with the config and set the ‘mode‘ argument to ‘inference‘ instead of ‘training‘.
[ ]
create config
cfg = PredictionConfig()
define the model
model = MaskRCNN(mode=’inference’, model_dir=’./’, config=cfg) Next, we can load the weights from our saved model.
We can do that by specifying the path to the model file. In this case, the model file is ‘mask_rcnn_kangaroo_cfg_0005.h5‘ in the current working directory.
[ ]
load model weights
model.load_weights(‘mask_rcnn_kangaroo_cfg_0005.h5’, by_name=True) Next, we can evaluate the model. This involves enumerating the images in a dataset, making a prediction, and calculating the AP for the prediction before predicting a mean AP across all images.
First, the image and ground truth mask can be loaded from the dataset for a given image_id. This can be achieved using the load_image_gt() convenience function.
[ ]
load image, bounding boxes and masks for the image id
image, image_meta, gt_class_id, gt_bbox, gt_mask = load_image_gt(dataset, cfg, image_id, use_mini_mask=False) Next, the pixel values of the loaded image must be scaled in the same way as was performed on the training data, e.g. centered. This can be achieved using the mold_image() convenience function.
[ ]
convert pixel values (e.g. center)
scaled_image = mold_image(image, cfg) The dimensions of the image then need to be expanded one sample in a dataset and used as input to make a prediction with the model.
[ ] sample = expand_dims(scaled_image, 0)
make prediction
yhat = model.detect(sample, verbose=0)
extract results for first sample
r = yhat[0] Next, the prediction can be compared to the ground truth and metrics calculated using the compute_ap() function.
[ ]
calculate statistics, including AP
AP, _, _, _ = compute_ap(gt_bbox, gt_class_id, gt_mask, r[“rois”], r[“class_ids”], r[“scores”], r[‘masks’])
The AP Values can be added to a list, then the mean value calculated.
Tying this together, the evaluate_model() function below implements this and calculates the mAP when given a dataset, model and configuration.
[ ]
calculate the mAP for a model on a given dataset
def evaluate_model(dataset, model, cfg): APs = list() for image_id in dataset.image_ids: # load image, bounding boxes and masks for the image id image, image_meta, gt_class_id, gt_bbox, gt_mask = load_image_gt(dataset, cfg, image_id, use_mini_mask=False) # convert pixel values (e.g. center) scaled_image = mold_image(image, cfg) # convert image into one sample
Running the example will make a prediction for each image in the train and test datasets and calculate the mAP for each.
A mAP above 90% or 95% is a good score. We can see that the mAP score is good on both datasets, and perhaps slightly better on the test dataset, instead of the train dataset.
This may be because the dataset is very small, and/or because the model could benefit from further training.
Detecting Kangaroos in new Images